The problem
How to estimate the disk usage of a table, given the DDL and the number of rows.
The short answer
The disk usage of a table is mainly composed of two parts: row data and index data.
For the row data, we use this simplified formula:
(4byte + 24byte + the size of a single row determined by the datatype of each column) * row count
For the B tree index, we use this simplified formula:
(4byte + 8byte + the size of columns composing the index) / 0.9 * row count
For those who are curious, 0.9 in the above formula is the default fillfactor of leaf pages of B tree index.
Notice that the size of a single row data or index data should be aligned to multiple of the MAXALIGN(which is usually 8).
For example, if the total size of all columns in the index is 6 byte, we should use 8 byte in the above formula.
An example
Assume the disk usage of the following table needs to be estimated.
We will insert some data into it and compare the actual data size and estimated data size to justify the two formulas above.
--DDL of the table CREATE TABLE todo_item ( id serial NOT NULL, name text NOT NULL, completed boolean NOT NULL, CONSTRAINT todo_item_pkey PRIMARY KEY (id) ); --insert 100,000 rows into the table --to simplify the problem, all the text values are the same size. INSERT INTO todo_item (name, completed) select md5(s::text) as name, false as completed from generate_series(1,100000) as s; -- get the actual disk usage of the table SELECT relname, reltuples, (relpages * 8) as kbytes FROM pg_class WHERE relname like 'todo_item%';
Comparison
As is shown in the following table, the estimated disk usage and the actual one are quite close, so we can use the formulas with confidence.
| Estimated | Actual | |
|---|---|---|
| Table data | 6640KB | 6672KB |
| Index data | 2170K | 2208K |
Under the hood
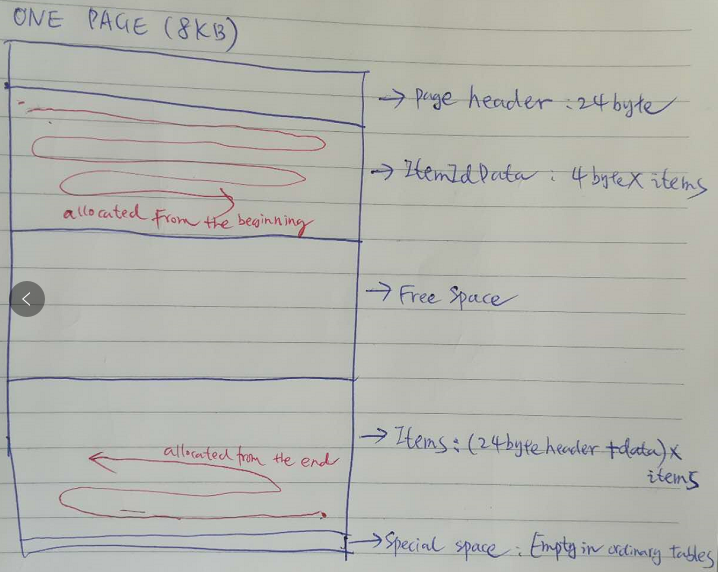
Every table and index is stored as an array of pages of a fixed size (usually 8 kB), the layout in a single page of table data and that of index data are the the quite similar.
The following sketch shows the layout of a page of table data. The formulas above will be understandable with the help of the sketch.